Every week, another headline announces that AI will transform manufacturing. Foundation models will optimize your supply chain. Large language models will write your safety reports. Generative AI will design your next product.
The reality on the factory floor is different. Over 90% of industrial AI projects stall at the proof-of-concept stage. The models that write poetry and generate photorealistic images struggle to read a P&ID, predict when a compressor bearing will fail, or optimize a distillation column without violating safety constraints.
This is not a temporary gap that the next GPT release will close. It is a structural mismatch between how generic AI systems are built and how manufacturing actually works.
This article draws on recent academic research and industry analysis to explain why generic AI fails in manufacturing — and what a purpose-built alternative looks like.
The Foundation Model Illusion
Foundation models — large neural networks pre-trained on massive datasets and fine-tuned for downstream tasks — have produced remarkable results in language, vision, and code generation. The natural assumption is that these models can be extended to any domain, including industrial manufacturing.
Recent research challenges this assumption directly.
A 2025 study published in Engineering examined whether current foundation models are ready for the process industry — petrochemicals, chemicals, metallurgy, and other continuous manufacturing operations. The authors found that general-purpose foundation models cannot handle the diversity of multi-industry process data, lack what they call "mechanism cognition" (understanding of the underlying physics and chemistry), and fail to meet the reliability and safety requirements of industrial environments.
The core problem: foundation models are trained on internet-scale text and images. They have never seen the inside of a distillation column. They do not understand reaction kinetics. They cannot reason about pressure relief valve sizing or interpret the difference between a control valve and a block valve on a process flowsheet.
A parallel survey on Industrial Foundation Models (IFMs) from the Journal of Intelligent Manufacturing reinforces this finding. The authors argue that horizontal, general-purpose models are fundamentally limited for manufacturing because they cannot account for the heterogeneity of industrial data — the mix of time-series sensor data, engineering drawings, maintenance logs, simulation files, and operational procedures that characterize real manufacturing environments.
Generic foundation models have seen billions of web pages but zero process flow diagrams, zero DCS historian exports, and zero HAZOP worksheets.
Manufacturing Data Is Not Internet Data
The success of foundation models in consumer applications rests on a critical assumption: data is abundant, clean, and standardized. The internet provides trillions of text tokens in consistent formats. ImageNet contains millions of labeled photographs with clear objects against distinct backgrounds.
Manufacturing data violates every one of these assumptions.
Sparse, multirate, and unlabeled
Chemical plants generate data from thousands of sensors, but this data is:
- Multirate — temperature sensors sample every second, lab analyses come every 8 hours, maintenance inspections happen monthly
- Sparse — fault events are rare; a compressor might fail once in five years, giving you exactly one training example
- Unlabeled — operators know something went wrong but rarely tag the root cause in structured form
- Noisy — sensor drift, calibration errors, and manual overrides contaminate the signal
A review in Chemie Ingenieur Technik on the machine learning lifecycle in chemical operations found that 70% of project effort goes to data preparation — not model building. Engineers spend months cleaning historian exports, aligning timestamps, filling missing values, and reconciling inconsistent tag naming conventions across different plant areas.
Generic AI platforms skip this step entirely. They assume your data is ready. It never is.
Legacy systems and integration nightmares
Most chemical plants run on control systems (DCS, SCADA) that were installed 10–30 years ago. Data formats are proprietary. Historian systems (PI, IP.21, DeltaV) each have their own APIs, data models, and quirks. Engineering documents live in a mix of AutoCAD, PDF, scanned paper, and SharePoint folders with inconsistent naming.
A plug-and-play AI that expects a clean API endpoint or a CSV upload cannot operate in this environment. It needs custom data pipelines built by engineers who understand both the data infrastructure and the process being measured.
Concept drift
Unlike static datasets, manufacturing processes change continuously:
- Catalysts degrade over their cycle life
- Feedstock compositions vary by supplier and season
- Equipment ages and operating envelopes shift
- Process modifications alter flow paths and control strategies
A model trained on last year's data may produce dangerously wrong predictions this year. The ML lifecycle paper documents how concept drift causes model performance to degrade rapidly post-deployment in chemical operations — yet generic AI platforms provide no built-in mechanism for detecting or adapting to this drift.
The Domain Gap: When Internet Models Meet Industrial Reality
Perhaps the most striking evidence of generic AI's failure comes from computer vision.
Foundation vision models like SAM (Segment Anything Model) and CLIP achieve impressive results on standard benchmarks — natural photographs of objects, animals, and scenes. Researchers recently tested these same models on real industrial data: Scanning Acoustic Tomography (SAT) images used for semiconductor defect inspection.
The results were stark. Models that achieved high accuracy on pet photos and street scenes scored near-zero Intersection over Union (IoU) on industrial SAT images. The domain gap between internet images and industrial imaging modalities was so large that the models produced essentially random output.
This is not a fine-tuning problem. The visual features that these models learned — edges of cats, textures of buildings, shapes of cars — have no correspondence to the grayscale patterns in acoustic tomography, X-ray inspection, or the dense line-and-symbol layouts of engineering drawings.
For chemical engineering specifically: a generic vision model looking at a P&ID sees a confusing jumble of lines and circles. A domain-trained model sees a heat exchanger connected to a control valve with a bypass line, tagged E-201 and CV-104, in a feed preheat service. The difference is not incremental — it is categorical.
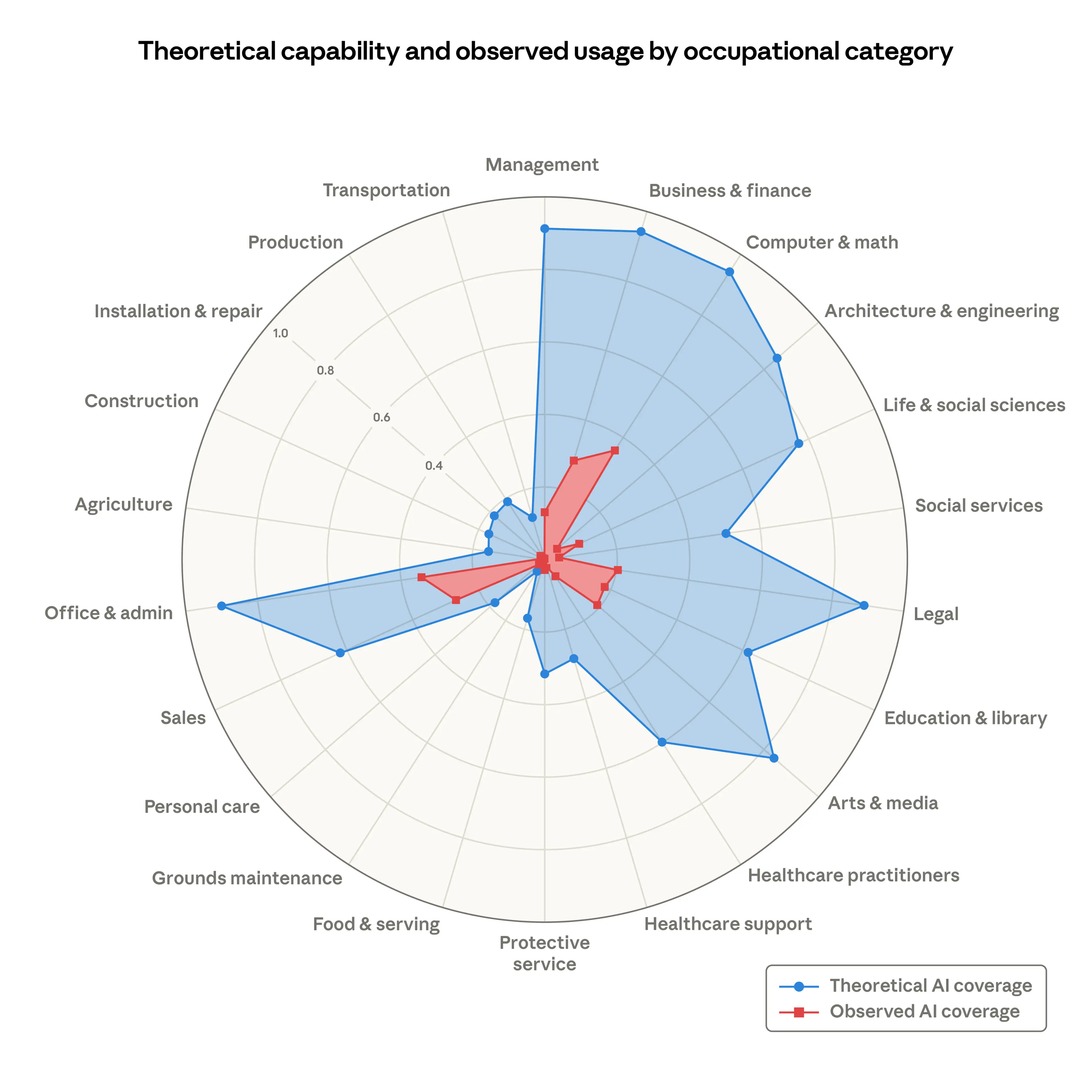
Research shows a massive gap between theoretical AI capability and actual observed usage. In architecture, engineering, and production — the categories most relevant to manufacturing — observed AI adoption lags far behind theoretical potential. This gap exists precisely because generic AI tools were not built for these domains.
Chemical Plants Are Not Click-Through Optimization
Most commercial AI has been optimized for a single objective: maximize revenue, click-through rate, or engagement. Manufacturing optimization is fundamentally different.
Multi-objective, physics-constrained
A chemical process engineer optimizing a reactor must simultaneously consider:
- Yield — maximize product output
- Energy consumption — minimize steam, electricity, and cooling water usage
- Safety — stay within temperature, pressure, and concentration limits at all times
- Emissions — meet environmental regulatory targets
- Throughput — match production to demand schedules
- Equipment life — avoid operating conditions that accelerate degradation
These objectives often conflict. Increasing throughput raises energy consumption and may push operating conditions closer to safety limits. Minimizing energy use may reduce yield. A model that optimizes one variable without respecting the constraints on others is not useful — it is dangerous.
Generic AI has no concept of these physical constraints. An LLM asked to "optimize this reactor" has no way to verify that its recommendations respect thermodynamic feasibility, reaction kinetics, or equipment design limits. It can only pattern-match against text it has seen before, with no guarantee that the output is physically realizable.
Nonlinear dynamics and real-time adaptation
Process manufacturing involves nonlinear thermodynamics, complex reaction kinetics, and fluid mechanics that create highly coupled systems. A change in feed temperature affects reaction rate, which affects heat generation, which affects cooling requirements, which affects downstream separation performance.
The Engineering study on process industry foundation models notes that these systems require real-time adaptation to dynamic changes in raw materials, equipment performance, and environmental conditions. Generic AI models that produce static recommendations based on training data cannot handle this level of dynamism.
Furthermore, industrial process control already has decades of sophisticated domain-specific tools: Advanced Process Control (APC) systems, Model Predictive Controllers (MPC), and real-time optimization (RTO) systems. Any AI solution must integrate with — not replace — this existing infrastructure. An LLM that cannot communicate with a DeltaV DCS or read a Honeywell UniSim model is operationally irrelevant.
The Lifecycle Problem: Why 90% of PoCs Never Scale
Building a model is the easy part. Deploying it in a live plant, keeping it accurate, and gaining operator trust is where most AI projects die.
The machine learning lifecycle in chemical operations exposes several critical gaps:
Deployment infrastructure
Moving from a Jupyter notebook to a production system that runs 24/7 in a plant network — behind firewalls, on older operating systems, without reliable internet — requires engineering that generic AI platforms do not provide. Models need to handle network interruptions, data pipeline failures, and historian outages gracefully.
Monitoring and retraining
Once deployed, who watches the model? Most generic platforms provide no built-in monitoring for concept drift, data quality degradation, or prediction accuracy decline. In a chemical plant, an undetected model failure does not just produce a wrong recommendation — it can trigger a safety incident.
The CRISP-ML(Q) framework emphasizes the need for quality assurance across every stage of the ML lifecycle: problem understanding, data engineering, model building, evaluation, deployment, and monitoring. Most generic AI tools focus exclusively on model building.
Regulatory validation
Chemical plants operate under strict regulatory frameworks: OSHA Process Safety Management (PSM), EPA Risk Management Programs (RMP), IEC 61511 for Safety Instrumented Systems. Any AI system that influences operations must be validated against these standards. Generic AI platforms are not designed for this level of regulatory scrutiny.
Organizational Barriers: It's Not Just the Model
A 2025 empirical study published in the Journal of Manufacturing Technology Management surveyed manufacturing firms to identify why they struggle with AI adoption. The barriers extend far beyond model accuracy:
- Data quality and legacy systems — organizations lack the data infrastructure to feed AI models, and integrating with decades-old systems requires specialized expertise
- Skills gap — there are very few people who understand both data science and process engineering; most AI vendors send data scientists who don't know what a HAZOP is, and most plant engineers don't know what a transformer architecture is
- Unclear ROI — generic AI vendors promise vague "efficiency gains" without concrete, measurable outcomes tied to specific process improvements
- Resistance to change — operators with 20 years of experience are skeptical of recommendations from a system that was trained on internet text
- Trust deficit — black-box models that cannot explain their reasoning are rejected by engineers who need to understand why before they change an operating setpoint
The study reinforces what practitioners already know: successful AI adoption in manufacturing requires domain expertise delivered alongside the technology. You cannot ship a SaaS login and expect a plant to transform itself.
What Domain-Specific AI Should Look Like
The failure modes of generic AI point directly to the requirements for industrial AI that actually works:
Built on industrial data, not internet data
Models must be trained on actual process industry data: engineering drawings, process historian exports, maintenance records, safety reports, and simulation files. This data is not available on the internet. It must be collected, labeled, and curated in partnership with operating plants.
For P&ID recognition, this means training on real engineering drawings across ISA 5.1, ISO 14617, and proprietary symbol sets from different companies, eras, and CAD tools. A model trained on a narrow dataset fails on the next plant. A model trained on diverse, real-world data generalizes.
Physics-informed, not pattern-matching
Industrial AI must respect the underlying physics. This means integrating domain knowledge into model architectures: thermodynamic constraints, mass and energy balances, equipment design limits, and safety boundaries. The Engineering process industry study calls this "mechanism cognition" — the ability to reason about why a process behaves the way it does, not just what patterns exist in the data.
Hybrid approaches that combine physics-based models with data-driven methods outperform pure machine learning in manufacturing. They require less data, generalize better, and produce predictions that are physically consistent.
Full lifecycle support, not just models
Deployment is not a one-time event. Industrial AI requires:
- Data pipelines that handle the messiness of plant data infrastructure
- Continuous monitoring for drift, data quality, and prediction accuracy
- Retraining workflows that incorporate new data and operator feedback
- Validation processes that satisfy regulatory requirements
- Integration with existing DCS, historian, and engineering tools
Domain expertise embedded in delivery
The skills gap cannot be solved with documentation. It requires engineers who understand both the AI technology and the industrial domain — who can walk a plant floor, read a P&ID, and configure an AI system to match the specific equipment naming conventions, safety standards, and operating procedures of that facility.
This is why we embed on-site engineers at every deployment. They learn your workflows, your equipment, your standards. They configure AI systems that understand your plant — not a generic chemical engineering textbook, but your actual operations. Most teams are up and running within six weeks.
Edge deployment and data sovereignty
Plant data is sensitive. Process conditions, equipment performance, and safety records are proprietary. Manufacturing AI must run locally — on-premises or at the edge — with full data sovereignty. Cloud-only architectures are rejected by most plant operators for good reason.
The Path Forward
The gap between AI hype and manufacturing reality is not closing on its own. Larger models trained on more internet data will not learn to read P&IDs. More powerful GPUs will not solve the concept drift problem. Better prompt engineering will not make an LLM understand reaction kinetics.
What closes the gap is vertical AI — purpose-built systems designed for specific industrial domains, trained on domain-specific data, delivered by domain experts, and maintained through the full operational lifecycle.
The research is clear: generic AI achieves generic results. In an industry where a wrong prediction can mean an environmental release, a safety incident, or millions of dollars in lost production, generic is not good enough.
Manufacturing deserves AI built for manufacturing.
References
-
"Foundation Models for the Process Industry." Engineering, 2025. Analysis of why current general-purpose foundation models fail in process manufacturing and a framework for industrial alternatives.
-
"Industrial Foundation Models (IFMs) for Intelligent Manufacturing." Journal of Intelligent Manufacturing, 2025. Survey of industrial foundation models highlighting limitations of horizontal AI and data heterogeneity challenges.
-
"Generative AI in Manufacturing: A Literature Review." ScienceDirect, 2025. Review of generative AI applications in manufacturing, including data challenges, robustness, and explainability limitations.
-
"A Review of Artificial Intelligence and Industrial Chemical Processes." FOSM Journal. Benefits and limitations of AI in chemical manufacturing, with emphasis on data needs and human oversight requirements.
-
"The Machine Learning Life Cycle in Chemical Operations — Status and Open Challenges." Chemie Ingenieur Technik, Wiley. Analysis of deployment, monitoring, and data preparation challenges for ML in chemical plants.
-
"Why Do Manufacturing Firms Struggle with Artificial Intelligence?" Journal of Manufacturing Technology Management, 2025. Empirical study on organizational barriers to AI adoption: data quality, legacy systems, skills gap, and unclear ROI.
-
"Are Foundation Models Ready for Industrial Defect Recognition? A Reality Check on Real-World Data." Literature review showing near-zero performance of SAM/CLIP models on real industrial imaging data.
-
"How AI Enables New Pathways in Chemicals." McKinsey & Company. Industry analysis of real-time optimizers, control-room copilots, and integration requirements for chemical operations.